
Analyze Jira Issues using BigQuery and Data Studio
This post is started from my frustation trying to analyze Jira issues using Jira report features. Jira provides built-in reports, for example if you have a Kanban board it will provide Control Chart. However, if you want to customize the insight, the only way that I find is by doing a lot of coding, which is not flexible enough for me to do ad hoc analysis. I ended up copying Jira issue to BigQuery so that I can analyze easily.
Using Jira API to Get Jira Issues
I am using Python JIRA library to do the work. Since I’m going to analyze the data regularly, I schedule a script on Cloud Composer that query Jira data and then upload to BigQuery. The first part is getting API authenticaion detail. You will need server, user, and API key to work with. Here’s the sample value:
jira_user = 'mrawesome@abcd.com'
jira_apikey = 'xxx'
jira_server = 'https://abcd.atlassian.net/'
Then, we need to design how the JQL query will be. JQL, stands for Jira Query Language, is a query language we will use to get issues from Jira API. I am planning run this script daily, take all issues created on yesterday’s date in project ABCD. Here’s my JQL example using hardcoded date.
jql = 'project = "ABCD" AND created >= "2019/06/28" AND created < "2019/06/29"'
Since I am going to load it into BigQuery, I write it first as json file locally. Here’s how the complete script looks like.
import os, json, copy
from jira import JIRA
jira_user = 'mrawesome@abcd.com'
jira_apikey = 'xxx'
jira_server = 'https://abcd.atlassian.net/'
jql = 'project = "ABCD" AND created >= "2019/06/28" AND created < "2019/06/29"'
temp_file_name = 'jira_created_2019-06-28.json'
prefix = 'jira_created/created=2019-06-28/'
jira = JIRA({'server': jira_server}, basic_auth=(jira_user, jira_apikey))
with open(temp_file_name, 'w') as fp:
for issue in jira.search_issues(jql,maxResults=max_result):
fp.write(json.dumps(issue.raw))
fp.write("\n")
Oops, Need to Cleanse the Data
After my first run on the script, I naively tried to load it into BigQuery via web UI, and I got some details to be cleansed:
- The query return ten thousands of custom fields, custom fields are fields defined by JIRA users. I need to exclude them as I’m not using them
- Object returned contains fields started with number, which is avatar fields: ‘16x16’, ‘32x32’, etc. Need to exclude them as well.
- The date returned is using ISO date time with letter ‘T’ to separate date and time, BigQuery refuse to process and say that we need to use space as date and time separator Then I created some functions to do those clean up and transformation before I write the issues to JSON.
Upload to GCS and Load to BigQuery
As it involves several steps already that should be decoupled, I decided to use Composer. Here’s how the DAG looks like.
with DAG(dag_id, schedule_interval=schedule_interval,
default_args=default_args) as dag:
jira_to_gcs = PythonOperator(
task_id='jira_to_gcs',
python_callable=jira_to_gcs,
op_kwargs={'bucket_name': gcs_bucket},
provide_context=True
)
gcs_to_bq = GoogleCloudStorageToBigQueryOperator(
task_id='gcs_to_bq',
bucket=gcs_bucket,
source_objects=[ 'jira_created/created=/*.json' ],
destination_project_dataset_table=destination_table_with_partition,
source_format=source_format,
create_disposition='CREATE_IF_NEEDED',
write_disposition='WRITE_TRUNCATE'
)
Finally, Time to Analyze the Data!
After several months backfill in several minutes only, we are ready to analyze the data on BigQuery. Start with a simple one, how’s the trend for issue based on priority? The query was only 5.3KB, which translate to almost $0 with $5 per TB current BigQuery query pricing.
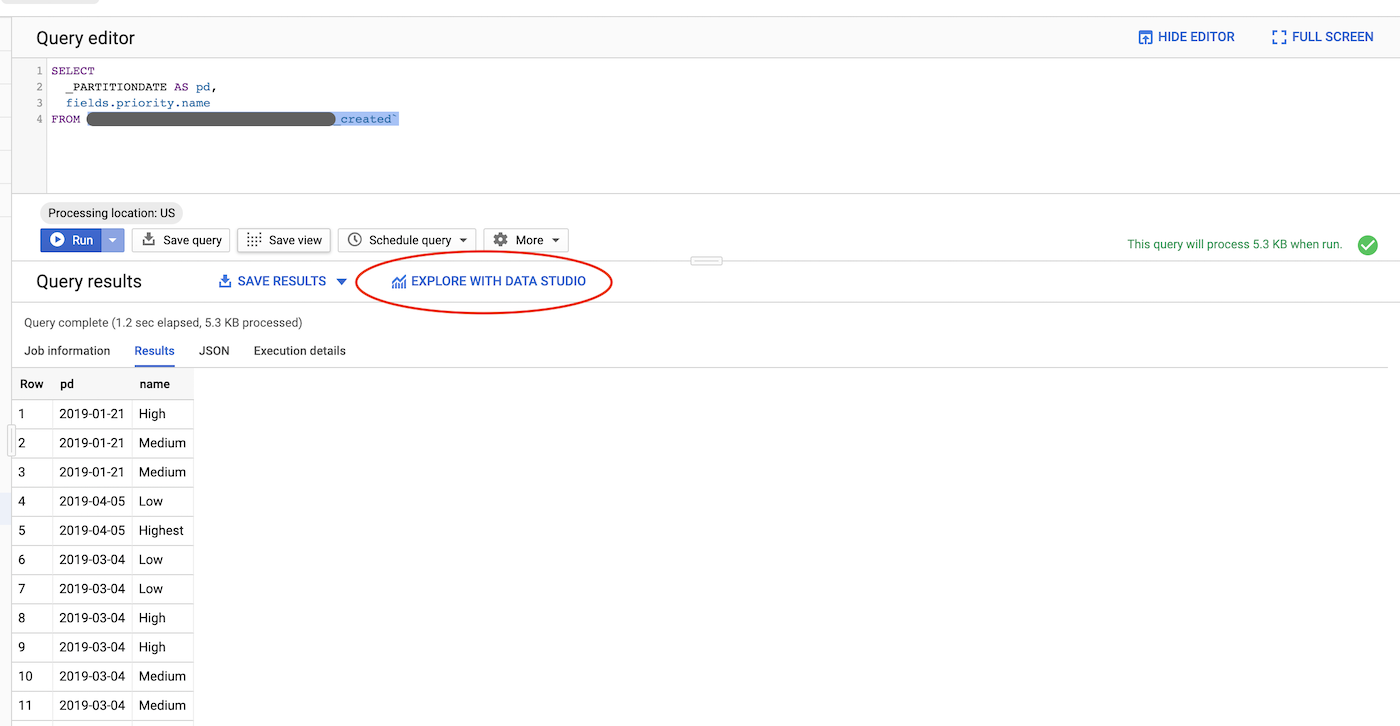
After this simple initial query, I clicked “EXPLORE WITH DATA STUDIO” on red circle above.
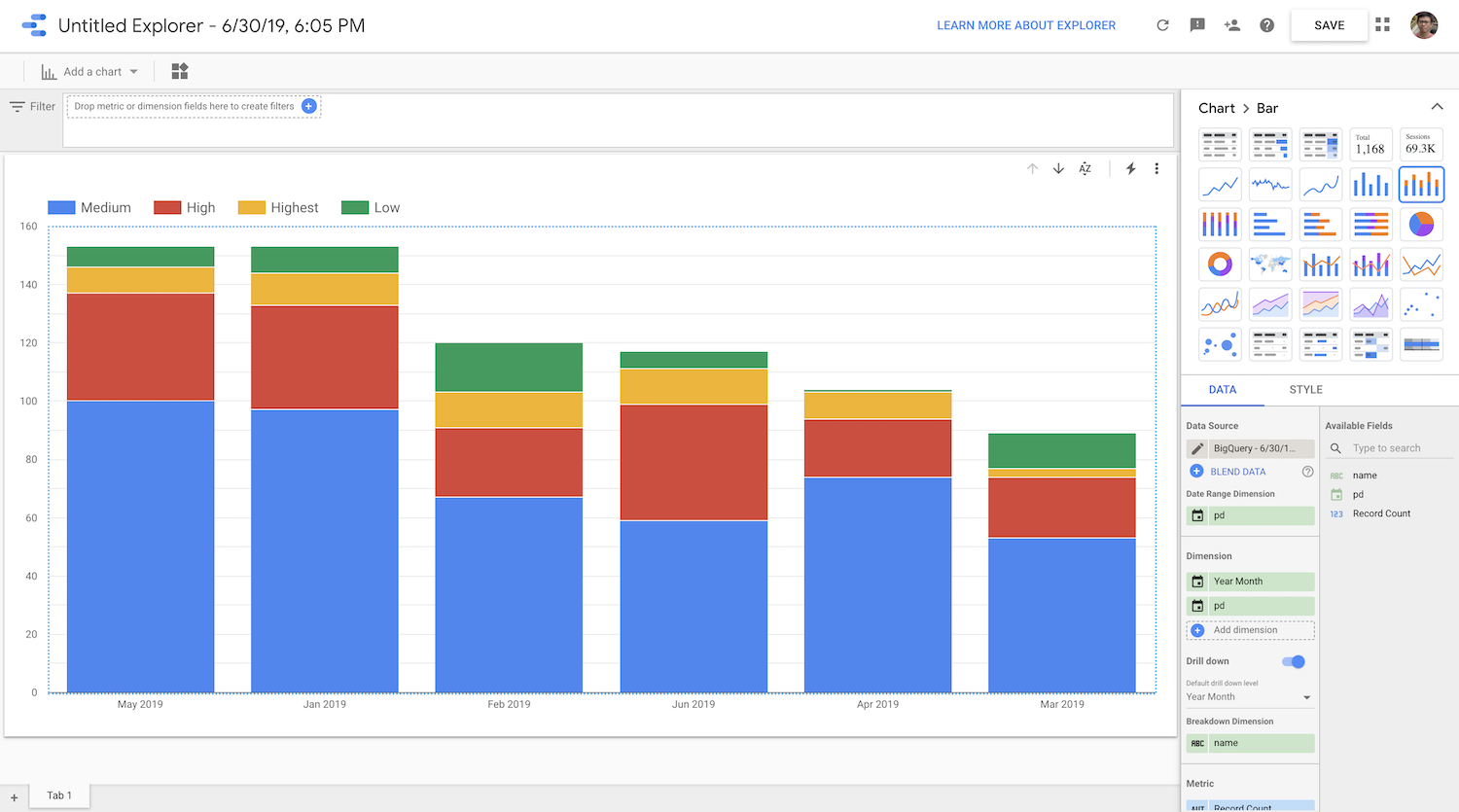
I am so happy now I can easily create my own insight and create my own queries to dig deeper on my Jira issues. :)



Leave a comment